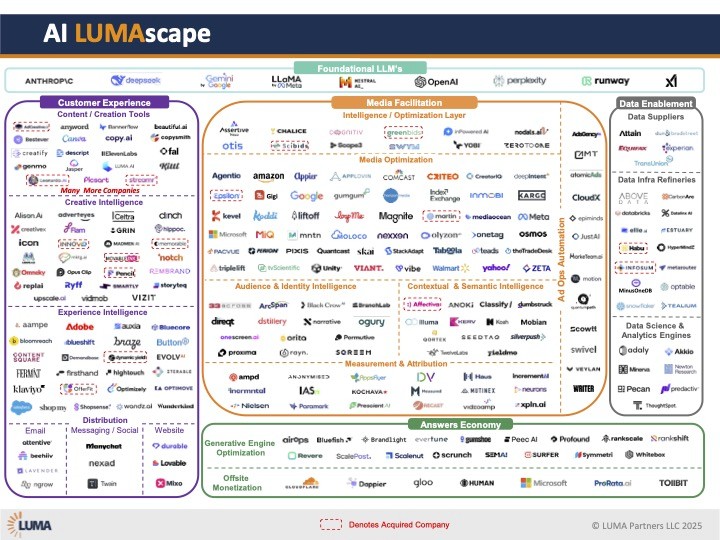
MinusOneDB just landed on the AI Lumascape under Data Infrastructure/Data Infra Refineries.
For those unfamiliar: LUMA Partners' Lumascapes are the industry standard maps that organize the chaos of digital technology ecosystems. They're referenced in boardrooms, classrooms, and investment decks. Getting on one means you're recognized as a legitimate player in the category.
But here's what's more interesting than the recognition itself: We're there because AI has a data infrastructure problem that nobody wants to talk about.
The Dirty Secret of AI Infrastructure
Everyone's excited about foundation models and LLMs. OpenAI raises billions. Anthropic raises billions. The headlines write themselves.
But here's what they don't tell you: These models are drowning in query costs - both to train them, and to use them on enterprise data.
When you're training on trillion-event datasets, when you're running continuous RLHF loops, when you're trying to build real-time model scoring infrastructure—the traditional data warehouses are extracting their pound of flesh.
And when you're an enterprise running AI to work with your large datasets - same pound of flesh.
At $10 per query per terabyte, a single exploratory analysis on a petabyte costs $10,000.
One. Single. Query.
That's not infrastructure. That's extortion.
Why MinusOneDB Belongs in AI Infrastructure
We didn't build MinusOneDB to be an "AI company." We built it because we saw the data warehouse for what it is: a business model that punishes exploration and innovation.
Here's what makes us essential for AI workloads:
1. Flat-rate pricing that makes experimentation possible
Train thousands of model variants, not just the five you can afford
Run continuous scoring without watching the meter
Let your AI actually learn from your data instead of rationing queries
2. Sub-10ms performance at petabyte scale
Real-time RLHF becomes actually real-time
Feature stores that update in seconds, not overnight batches
Model scoring that happens now, not tomorrow
3. Architecture built for AI's actual needs
Write costs dramatically lower than legacy platforms (revolutionary for AutoML)
Additive schema for rapid feature engineering — add typed properties without migrations
True streaming ingest for continuous learning
For Foundation Model Builders: Stop Bleeding Cash on Training
If you're building the next GPT, Claude, or Gemini, you know the pain:
Training data management: Organizing and querying trillion-token datasets is expensive and query-heavy
RLHF infrastructure: Real-time human feedback loops require instant query responses, not batch processing
Model versioning chaos: Testing hundreds of model variants means millions of scoring operations
Feature engineering bottlenecks: Every new signal requires expensive recomputation
MinusOneDB changes the game:
Unlimited experimentation on your training corpus without per-query penalties
Real-time feedback integration with sub-second index visibility
Parallel model evaluation across thousands of variants simultaneously
10x faster iteration cycles from hypothesis to production
For AI Application Builders:
Building on top of LLMs and enterprise data scales? Your challenges are different but equally expensive:
True agentic exploration: Your AI could run 1,000 queries to investigate a problem in a 10TB dataset. Instead it runs 3 (if you’re lucky) and guesses. Why? Because those 1,000 queries would cost $100,000+ on traditional infrastructure
Context window optimization: Finding the right context requires exploring massive datasets
Personalization at scale: Every user interaction needs instant data retrieval
Compliance and governance: Audit trails and data lineage for every AI decision
Traditional infrastructure makes these use cases prohibitively expensive. MinusOneDB makes them trivial:
Dynamic context assembly from petabyte-scale knowledge bases
Per-user model customization without pre-computing every possibility
Complete audit trails without performance penalties
The marginal cost of curiosity is zero: Let your agents explore, investigate, and discover - not just sample
A major advertising client used us to build real-time audience creation for AI-driven campaigns. Query times went from 10 minutes to 10 seconds, and incremental queries became effectively free.
The Reality Check
The companies building foundation models need infrastructure that doesn't treat every query like a profit center. The enterprises deploying AI need systems that can handle millions of queries without making their applications too expensive to run. The startups innovating need to experiment without permission from the CFO.
What This Really Means
Being on the Lumascape isn't about bragging rights. It's validation of a simple truth: The current data infrastructure is broken for AI workloads.
While the cloud giants are busy protecting their 90% compute margins, we're delivering:
Massive cost reduction per-query versus traditional warehouses
Faster model iteration cycles
Infrastructure that scales with ambition, not invoices
The Path Forward
AI's potential is being throttled by infrastructure that was built for a different era. An era where queries were few, exploration was expensive, and "real-time" meant "sometime today."
That era is over.
MinusOneDB isn't just another logo on a crowded landscape. We're the infrastructure that makes the AI revolution actually affordable. We're the platform that lets data scientists ask "what if?" without asking "how much?"
We're not here to participate in the AI gold rush. We're here to provide the picks and shovels that actually work.
Ready to Stop Paying the Compute Tax?
If you're:
Running more than 1,000 uncacheable queries per month
Managing 1-25TB of data (or more)
Watching query costs eat your innovation budget
Building AI/ML systems that need to actually learn from data
Then let's talk. The compute cartel's days are numbered.
Contact us at [email protected]
Because your AI deserves infrastructure that doesn't punish curiosity.